Carbon Peak and Carbon Neutralization Information Support Platform
碳达峰碳中和情报支持平台

The Duplicate Review Checker screens peer reviews for suspicious content.Credit: Grace Cary/Getty A first-of-its-kind artificial-intelligence tool detects duplicate or suspiciously similar peer-review reports. The system — developed by Institute of Physics Publishing (IOPP), based in Bristol, UK — can help to uncover cases of plagiarized or template-like peer reviews, which individuals or organized groups use to push manuscripts through the publication process or boost citations to their own work. The technology aims to “combat this pressing issue”, said Lauren Flintoft, the IOPP’s research integrity manager, who presented the findings of a pilot study testing the tool at the 9th World Conference on Research Integrity in Vancouver, Canada on 4 May. Most integrity checks focus on manuscripts, but “peer-review process fraud is equally as important and targeted probably more often than you think by bad actors”, Flintoft told the meeting. In an analysis of around half a million peer-review reports for manuscripts submitted to the IOPP between 2020 and 2025, the AI tool identified nearly 2,500 reports that had at least 60% overlap with former reviewer reports, of which 785 reports had at least 80% overlap. Of the flagged cases, 89 were exact duplicates. The IOPP is rolling out the tool across all its journals, the publisher announced on 5 May. Review mills Two studies, of open-peer-review reports1,2 — which involve reviews being posted alongside published papers — discovered hundreds of reviews for manuscripts across different publishers that seem to have been copied from a template. These reports, for example, contained similar wording or identical typos, and commonly included citations of the reviewers’ own papers. Research-integrity sleuth Maria Ángeles Oviedo-García, who studies marketing at the University of Seville in Spain and co-authored both analyses, called these cases “review mills”. At the publisher PLOS, there have been “rising cases of peer-review integrity issues over the past few years”, says Renee Hoch, head of publication ethics in San Francisco, California. Scientists hide messages in papers to game AI peer review Between 2024 and 2026, PLOS investigated around 150 papers because of concerns about peer-review integrity. The publisher has so far retracted 40 articles and flagged 55 others as being under investigation. "A subset of these cases involved concerns about peer-review reuse or similarities", says Hoch. "I suspect that what we have seen and what has been reported publicly is only the tip of a very large iceberg," she adds. Two-stage screening In response to this growing problem, the IOPP built the Duplicate Review Checker (DRC) to screen peer-review reports in two stages. “The possibilities for the review mills are endless in the absence of plagiarism software for review reports,” said Flintoft. For every report, an AI model filters out the 50 most semantically similar peer-review reports in the publisher’s corpus. Then, a text algorithm compares the characters between these reports to spot exact matches and flag what proportion of their text overlaps. This AI can improve your peer review — and make it more polite The DRC flagged reviewer reports that seemed to follow a template and offered “no insight or constructive criticism for the authors”, Flintoft said. The suspicious reports were more commonly submitted by individuals, rather than many members of a group. But there were cases that might resulted from “an agreement between individuals to inflate citation scores”, added Flintoft. Peer reviews that were flagged by the DRC and linked with published papers in IOPP’s collection of journals are being investigated, the publisher told Nature. Collective effort Because peer-review reports are typically confidential, duplicate reports across publishers can be hard to detect. “The tool will be much more useful if other publishers buy into it as well and share their peer-review reports,” says René Aquarius, a science sleuth and neurosurgery researcher at Radboud University Medical Center in Nijmegen, the Netherlands. The IOPP is planning to share their tool with other publishers, said Flintoft at the meeting. Hoch welcomed the initiative. “Detection of these issues is only the first step. Publishers then face difficult decisions about how to proceed with the affected articles — which may report legitimate research,” she adds.
发布时间:2026-05-06 Nature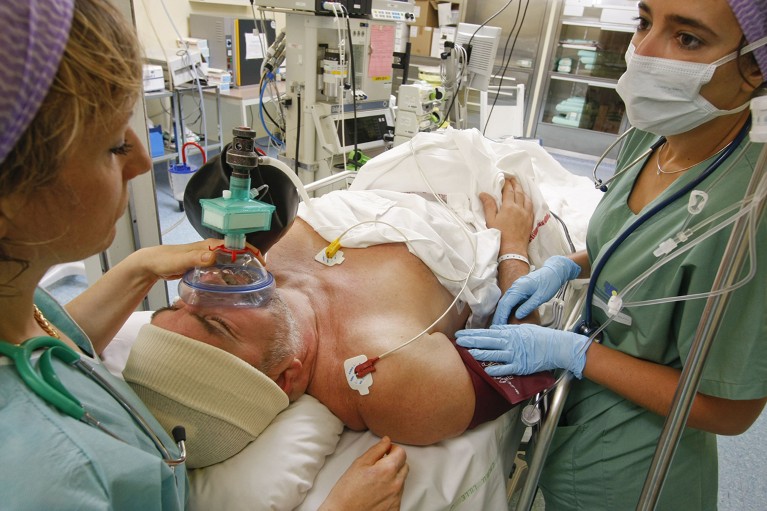
The brains of people under general anaesthesia continue to process words and sounds, a study finds.Credit: BSIP/UIG Via Getty People given general anaesthesia fall into a coma-like state in which their memory and perception of pain are switched off. But new data reveal that the hippocampus — a deep brain structure crucial for memory — remains remarkably active, parsing the grammar and meaning of spoken words and even anticipating what will be said next. Anaesthetized brains can still process podcasts The research, published today in Nature1, challenges the assumption that complex cognition, such as grasping semantics and forecasting future events, can occur only if a person is fully conscious. By observing people’s individual neurons firing in real time while they are under anaesthesia, researchers discovered that the brain receives stimuli and actively processes what those signals mean. “The brain has developed such amazing, sophisticated mechanisms for doing all these complex tasks all day long, that it can do some of these things even without us being aware,” says Sameer Sheth, a neurosurgeon at Baylor College of Medicine in Houston, Texas. Probing the unconscious brain Previous studies have shown2 that the parts of the brain that first detect sensory input can still register simple sounds while a person is unconscious. But it has remained unclear whether other, deeper regions of the brain are capable of complex cognition while someone is unconscious. To address this, Sheth and his colleagues recorded the brain activity of seven people anaesthetized with the drug propofol while they were undergoing surgery to treat epilepsy. How to detect consciousness in people, animals and maybe even AI The researchers played a series of repetitive beeps interspersed with tones of a different pitch to three of the participants. Over the course of ten minutes, the brain recordings showed that the anaesthetized hippocampus becomes better at differentiating the tones and the beeps, suggesting a form of unconscious learning. The team also played ten-minute podcast segments to four of the study participants and observed that specific neurons were responding to certain parts of speech, distinguishing nouns from other words, for instance. The neurons also anticipated upcoming words on the basis of the context of the sentence. “They were literally predicting what the next word is going to be,” Sheth says. Comparing these participants’ data with those of a control group of awake participants who did a similar podcast-listening task revealed that both groups performed at a comparable level. Typically, the electrodes that researchers use to monitor the brain record the average activity of a group of thousands of cells, but Sheth and his colleagues used advanced probes called Neuropixels. These electrodes are thinner than a human hair and can therefore simultaneously record individual signals from hundreds of neurons, providing a more fine-grained look at activity in the hippocampus. The Neuropixels offer a “much more precise lens” for peering into the brain than was previously available, says Martin Monti, a cognitive neuroscientist at the University of California, Los Angeles. “This study pushes the bar a little higher for how much a small patch of neurons can do under anaesthesia — the answer is, surprisingly, a lot.” Communication disruption Monti cautions that these findings shouldn’t be interpreted to mean that participants were secretly awake or fully conscious. Propofol is known to disrupt coordinated brain network communication, which many researchers say is a necessary ingredient for consciousness. What the study does show, Monti says, is that this one structure — the hippocampus — computes and integrates information even under anaesthesia. Still conscious? Brain marker signals when anaesthesia takes hold The findings could eventually be used in the clinic. Sheth hopes to perform similar experiments on people with severe traumatic brain injuries who are in a coma or vegetative state. Because these individuals are already unconscious owing to their injuries, researchers want to know whether their brains still harbour isolated regions that can process language and predict speech. If they do, these data might one day guide future therapies — such as targeted brain stimulation — to bypass damaged neural pathways and artificially reconnect those regions with the rest of the brain. Sheth says he hopes to repeat the experiment with other types of anaesthesia, to confirm that the results are universal. He would also like to play podcasts in foreign languages to people under anaesthesia to see whether the unconscious brain still attempts to parse the structure of the speech, even if participants don’t comprehend the language.
发布时间:2026-05-06 Nature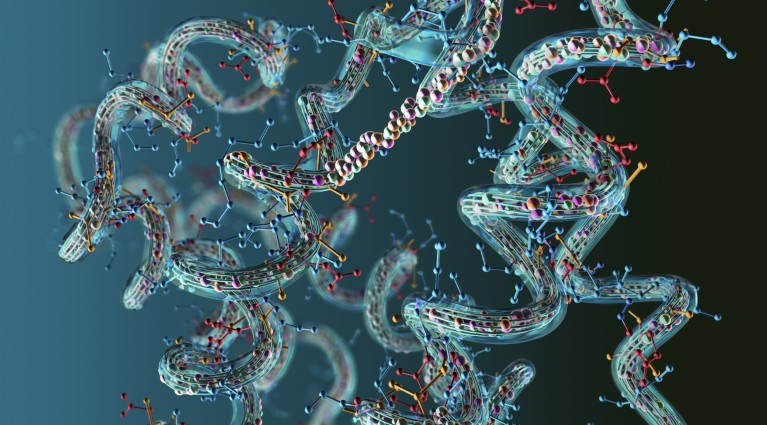
Some proteins (artist’s illustration) are being reclassified in databases as a result of the latest findings.Credit: Christoph Burgstedt/Getty The human genome contains around 20,000 genes that hold instructions for making working proteins, as most genetic databases now indicate. However, some scientists say there might be thousands more ‘dark proteins’ with unknown but potentially important roles in cells. These proteins, the code for which has been translated from portions of the genome that weren’t thought to produce proteins, were excluded from official genome and protein counts. An effort announced today in Nature1 gives thousands of these molecules encoded by the human genome an official, new name — peptideins — and marks their inclusion in major gene and protein databases used by the life-sciences community. Researchers say the rebranding will bring much-needed attention and effort to working out what different peptideins do in cells. Some have been implicated in diseases including childhood cancers, as well as in basic cellular functions. ‘Dark proteins’ hiding in our cells could hold clues to cancer and other diseases But what most of them do is unknown, although there is some evidence that many peptideins — previously called microproteins or non-canonical, ‘dark’ proteins — are cellular by-products without a clear function. “This is a major breakthrough,” says Christoph Dietrich, a bioinformatician at the University of Heidelberg, Germany. “These microproteins have the potential to really open up a new wave of research.” Short and mysterious Dark proteins tend to be very short in amino acid length and lack evolutionary relatives in other organisms, which is part of the reason they have been omitted from protein-coding gene and proteome databases. In many cases, they are encoded by genes that are very near to, or in some cases overlapping with known, protein-coding genes. In today’s Nature paper, a new effort called the TransCODE Consortium analysed experimental data on thousands of potential dark proteins. Starting with a list of 7,264 DNA sequences suspected to encode dark proteins, the consortium found that just 15 had enough experimental support to be considered for official catalogues of protein-coding genes. Move over, DNA: ancient proteins are starting to reveal humanity’s history Portions of thousands more could be detected in cells, but the experimental evidence was less strong; their functions were almost entirely unknown. These were dubbed peptideins, a portmanteau of peptide — a short stretch of amino acids — and protein. “It’s made of amino acids, but we don’t know what it does in terms of function. We don’t necessarily know that it does anything at this point. But we know it exists,” says Jonathan Mudge, a bioinformatician who works on the GENCODE database of protein-coding genes at the European Molecular Biology Laboratory’s European Bioinformatics Institute in Hinxton, UK, and a consortium member. Biology’s dwarf planets GENCODE and other databases are creating a new category for peptideins. Mudge says this should aid efforts to work out what they do by drawing the attention of other scientists. “In a way it’s like: you guys go out and tell us,” he says. Around ten sequences previously thought to encode dark proteins have been moved into official lists of protein-coding genes maintained by GENCODE, says Mudge. As evidence builds, he expects that more peptideins will be added to the list. Some ‘canonical’ proteins will also probably be reclassifed as peptideins, Mudge says, in much the same way as the discovery of thousands of dwarf planets orbiting the Sun forced astronomers to reclassify what had been considered a planet. “We think of this almost as a Pluto moment,” he says. Xuebing Wu, a molecular biologist at Columbia University in New York City, says he likes the idea of peptideins (and is OK with the name). “This is a very important study. It’s really foundational work for setting out the stage for more functional study of this new class of genes.” But Wu suspects that closer examination will show that some — but not all — peptideins will turn out to be by-products of the cells’ protein-making machinery, and not independent actors in the cell. His team has found that many are quickly degraded2. In the latest paper, researchers found signs that more than 50 of the peptideins were somehow essential to cells. Previous work showed that the molecules now called peptideins could be important drivers of some cancers3 — including an aggressive brain cancer that affects children4 — and crucial to heart function5. Consortium co-leader Sebastiaan van Heesch, a systems biologist at the Princess Máxima Center for Pediatric Oncology in Utrecht, the Netherlands, expects many more such insights to follow. “People can no longer turn a blind eye,” he says.
发布时间:2026-05-06 Nature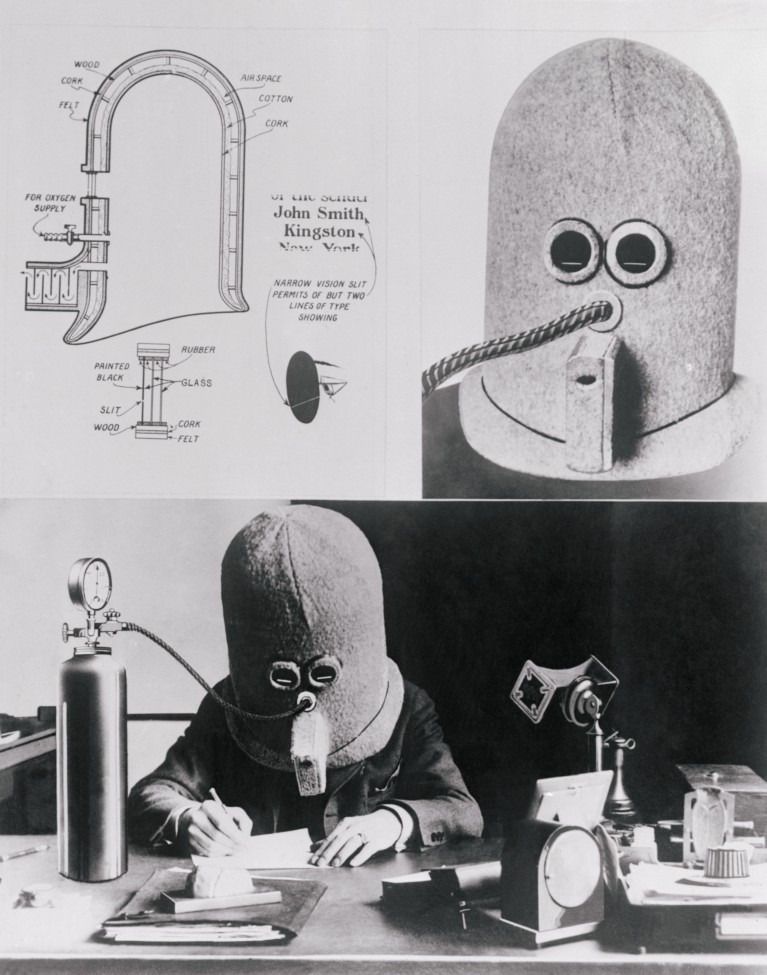
A century before social-media bans and advice to disable device notifications, the inventor and science-fiction writer Hugo Gernsback proposed a more extreme way to avoid distraction: an isolating wooden helmet. Outside influences, he said, were “the greatest difficulty that the human mind has to contend with”. Gernsback’s isolator device — part diving suit, part monastic cell — did help him to work, he said, but it came with a risk of suffocation. He later installed an air supply. Concerns that sustained thought is under assault have become even more acute in the digital era. Smartphones buzz, Internet tabs multiply and television episodes carry regular reminders to help people keep track of the plot. Surveys suggest that we feel less able to concentrate, teachers report distracted students and headlines declare that our attention spans are shrinking. Inventor Hugo Gernsback wearing his ‘isolator’ wooden helmet.Credit: Bettmann/Getty Research across psychology and neuroscience, however, has built up a more nuanced picture of what is happening to our attention spans. The results suggest that people do flit from one task to another more frequently than they did in previous decades, and that this switching is often detrimental to performance. But there is little evidence that the brain’s fundamental ability to concentrate has been impaired. This suggests that if we can shut down the distractions of our environment, it is possible to recover focus. “I think there’s a huge disconnect between what we feel like is happening and what is actually happening,” says Monica Rosenberg, a psychologist at the University of Chicago in Illinois. The attention-span confusion “There is a whole flurry of people reporting that they feel like they can’t pay attention,” says Nilli Lavie, a cognitive neuroscientist at University College London. “They say they are constantly distracted, their attention jumps from one thing to another, and they can’t concentrate.” In a 2021 survey of more than 2,000 UK adults, almost half said they felt their attention span was shorter than it used to be (see go.nature.com/4dfz8yc). And two-thirds thought that the attention span of young people has declined (see ‘Are attention spans waning?’). Teachers and schools around the world have responded to this perception with modular lessons that break topics into digestible pieces. Some students now study literary extracts rather than full novels. When the novelist Elif Shafak questioned why TED talks were becoming shorter, she said last year she was told that it was because “the world’s average attention span has shrunk”. Source: KCL Policy Inst./Centre for Attention Studies The idea of an average attention span carries intuitive appeal. But the way it’s discussed can tangle distinct concepts. Researchers distinguish between people’s capacity to pay attention, that is, their underlying ability to concentrate on a particular task, and their real-world behaviour, or what people actually focus on from moment to moment. What’s more, the capacity to pay attention is the result of several processes in the brain. These include sustained attention, the ability to stay engaged with a task over time; selective attention, the ability to prioritize some information and ignore the rest; and executive control, the ability to steer attention in line with a goal rather than whatever happens to be more tempting. Attention in the laboratory Capacity is measured under controlled laboratory conditions that test performance on a task — often a tedious one — over time. To test sustained attention, volunteers might monitor a screen showing streams of letters and shapes and identify specific changes. The ‘d2’ task, for instance, displays rows of letters, such as d and p, sometimes with dashes drawn above or below them, and asks people to mark the letter d only if it has two lines underneath. The ‘d2’ task used to test volunteers’ capacity for sustained attention in a laboratory. Nowadays, it is performed on a computer screen.Credit: Michael Szebor/Nature Many lab studies have shown how performance on such tasks declines in about ten minutes, although the pattern of decline is not smooth: even apparently strong attention naturally fluctuates between bursts of good performance, lapses and recovery. Further tests demonstrate how providing a distracting environment, such as playing sounds of babies crying and dogs barking, worsens people’s performance on cognitive tasks1. This provides a basis for understanding distractions in the real world. Analyses have demonstrated that, for instance, traffic accidents are more likely to occur if drivers are talking on their phones2. The lab studies haven’t shown evidence that — when free of distractions — people’s underlying capacity to pay attention has changed. But there are differences in how people perform. Those who say they frequently juggle several streams of media at once tend to perform worse on tests of selective attention, for example showing greater difficulty filtering out irrelevant information3. They also show differences in tests related to working memory and executive control4. ADHD diagnoses are growing. What’s going on? But these correlations might only reflect that individuals with different attentional tendencies could be naturally drawn to switch focus more often; the observations can’t prove that their digital environment has causally altered their brains. And although attention deficit hyperactivity disorder (ADHD) diagnoses have increased in recent years, researchers generally attribute the rise to changes in awareness and access to assessment and diagnostic practice, rather than to an underlying change in people’s attention capacity. Overall, there are no convincing data from controlled lab tests to support the idea that people have become less able to concentrate because the capacity of attention is being degraded over time. A 2024 meta-analysis of results from d2 tests performed by more than 21,000 people from 32 countries between 1990 and 2021 showed no differences in how children scored and, if anything, a slight improvement in adult performance5. “It’s not so much that human biology has changed, it’s more a change in habits. And the question is how reversible those habits are,” says Nelson Cowan, a psychologist at the University of Missouri in Columbia. Real-world measurements The strongest evidence for change when it comes to attention is not from laboratory tasks but from measures of real-world behaviour. For two decades, Gloria Mark, a psychologist at the University of California, Irvine, has monitored how office workers use computers. Her studies, based on direct observation and digital tracking, show that the average duration of attention to a single task has steadily declined. “We do know that attention spans on screens have measurably decreased,” she says. Mark’s work does not seek to measure sustained focus towards a specific goal. Instead, she counted when and how often workers switch between tasks. Such switches don’t have to be towards trivial distractions that would annoy the boss. They include opening a new browser tab, checking an e-mail and moving between documents, as well as glancing at a phone. In the mid-2000s, she says, she observed that workers spent about two and a half minutes on average on a dedicated screen task before switching. By the 2010s, that was down to about 75 seconds, and in the early 2020s it was about 47 seconds, according to Mark’s 2023 book6. Often included in discussion of these results is a 2015 marketing report by Microsoft Canada, which stated that the average human attention span had fallen from 12 seconds in 2000 to 8 seconds in 2013. The report noted that this was shorter than a goldfish’s average attention span, which it reported as 9 seconds (see go.nature.com/4e88mh9). But the report’s findings, based on surveys, filmed behaviour and electroencephalogram (EEG) data — which uses spikes in brain activity to measure when people switch their focus — reflected changing digital habits rather than cognitive limits and even noted that people were becoming more efficient at processing information. (Also, goldfish are unfairly maligned; there is no evidence that they have particularly short attention spans, and studies show they retain some information for months). Stress is wrecking your health: how can science help? Mark’s research shows that frequent switching of attention carries a cognitive cost. “When people switch, and especially when they switch fairly rapidly, which is what the data show, they tend to make more errors,” she says. “It takes them longer to accomplish any single task compared to if they were to do work sequentially, and stress goes up.” Constant switching also diverts the kind of mental effort used. “We’re not utilizing those skills of reflection, deliberation, working memory,” she says. This can lead to the familiar malaise of superficial busyness without seeming to make progress. Every generation has a panic that new technology will undermine the ability to concentrate. “But now we are in the digital age, and I do argue it’s different,” Mark says: both the scale of information available and the speed with which we can access it has changed. Importantly, the nature of the competing pulls on our attention has changed, too. The modern environment does not simply impose distractions. It bombards us with alternatives that offer more immediate rewards. People are switching tasks so often and resetting their attention each time because they choose to do so, even if they don’t realize it. “If the alternatives are really rewarding and high value, then it will be very hard to focus on something else that’s going to require more subjective effort,” says Michael Esterman, a neuroscientist at Boston University in Massachusetts. That’s ‘high value’ as classed by a psychologist or neuroscientist — which is not necessarily the way a parent, teacher or corporate superior would see it. Notifications, messages and social-media feeds provide the brain with bursts of social validation, novelty and information. Mark argues that these rewarding digital environments might be altering our attentional habits, including our tendency to drift even in the absence of obvious distraction. Her research suggests that the sources of interruptions are not solely external — such as the ping of an arriving message. “People are about as likely to self-interrupt as they are to be interrupted,” Mark says. And when external interruptions decrease, internal ones often increase — a pattern that suggests that distraction and switching can become habitual, she argues, and leave attention more fragmented. Are our brains actually changing? Real-world studies such as Mark’s are too messy to generate reliable data on specific aspects of brain performance. But Lavie also worries that this constant switching could relate to weaker executive control. She suggests that it could have long-term implications for the brain. Her work shows that the ability to control attention is linked to structural differences in the brain, specifically the amount of grey matter in regions of the frontal cortex. Using magnetic resonance imaging (MRI) scans and behavioural tests, she has shown that individuals with greater grey-matter volume in these areas perform better on tasks that require maintaining focus and resisting distraction7. The grey-matter volume can be used to make accurate predictions about how people will perform, and might reflect a combination of genetic factors and long-term experience. Cognitive neuroscientist Nilli Lavie instructs a volunteer on how to perform a task measuring attention; brain activity in this example is measured with an electroencephalogram (EEG) test. Credit: Attention and Cognitive Control laboratory, UCL Institute of Cognitive Neuroscience In principle, such measurements might be used to detect changes in attention capacity over time or between cohorts of people. Lavie doesn’t have the data to show that, and no such pattern has shown up in controlled lab studies, but she argues that it could happen. “There is the possibility that you either exercise it and it’s got a good grey-matter volume,” she says, “or you don’t, and it shrinks.” Rosenberg studies a different brain signature of attention. Using functional MRI, which measures brain activity, her team has identified patterns that link several systems, including the frontoparietal cortex, subcortical structures and the cerebellum, that together predict how well a person performs on sustained-attention tasks. These connectivity signatures are robust across individuals, populations and clinical groups, such as people with ADHD, and can be used to predict attention performance in people who haven’t been tested before8. Again, because patterns of connectivity can predict how well individuals perform on sustained-attention tasks, repeatedly scanning the same people could reveal whether that capacity is stable or changing. But Rosenberg’s studies so far are only snapshots or short-term, and focused on brain development rather than long-term changes. How to improve focus What does research on attention suggest about how we can improve our focus? “If we want to change our attention, then I think changing our environments will be much more effective than changing ourselves,” says Rosenberg. One way is to remove known sources of external distraction, especially those that offer short-term value and reward, even if the distraction seems faint. In some studies of cognitive tasks, people do worse if they have their phone in their pocket, even if it’s on silent9. Do smartphones and social media really harm teens’ mental health? Because attention naturally switches to high-reward distractions, another strategy is to artificially inflate the value of the task at hand. Payments for accuracy and consistency on attention tasks reduce lapses, produce fewer errors and can slow the rate of attentional decline over time10. In a job and getting paid already? Feedback, internal competition and clear goals can help to make accuracy and consistency feel important. So can a sense that what you are doing matters. If attention is shaped by habits, as Mark suggests, then it should also be possible to train and reverse those habits. Techniques such as mindfulness seem to strengthen the ability to notice when attention drifts and bring it back. Short breaks can restore performance. And distraction itself is not always the enemy. An important finding from controlled lab studies of attention is that even when volunteers have no external distractions, their minds still wander, often without conscious awareness that they have gone off task. Esterman, who has spent years studying these fluctuations11, argues that the flickering of attention must originate in the brain as useful internal processes that can distract us, including thoughts, ruminations and worries. Periods of mind-wandering can support creativity, planning and problem-solving, enabling the brain to explore and integrate ideas. Not only is sustained attention riddled with inevitable lapses, it is also shaped by mood, stress, sleep and anxiety, all of which influence both performance and how people interpret their own lapses. Negative moments loom large in memory, whereas successful concentration often passes unnoticed. Most importantly, the steady performance on the lab studies suggests that despite the competing attractions of the modern world, focus can still be found when we really need it. “We pay attention according to our goals,” Mark says. The question is what those goals have become. And if nothing else works, there’s always a wooden helmet.
发布时间:2026-05-06 NatureDownload the Nature Podcast 06 May 2026 In this episode: 00:42 Probing the unconscious brain’s processing ability Research Article: Katlowitz et al. Nature: Even the unconscious brain can learn — and predict what you’ll say next 12:32 Research Highlights Nature: An electrifying test to find a good coffee Nature: Forest pests hit trees hard as temperatures rise Subscribe to Nature Briefing, an unmissable daily round-up of science news, opinion and analysis free in your inbox every weekday. Never miss an episode. Subscribe to the Nature Podcast on Apple Podcasts, Spotify, YouTube Music or your favourite podcast app. An RSS feed for the Nature Podcast is available too.
发布时间:2026-05-06 Nature
Is testosterone the next miracle drug? That seemed to be the consensus of an expert panel convened by the US Food and Drug Administration (FDA) in December. It argued for major changes in policy that would expand access to the hormone for people with a range of conditions. Committee members called testosterone replacement “a cornerstone of preventive health” and “a multibillion-dollar preventive-care opportunity”. Testosterone is already available in the United States for people who have low levels of the hormone owing to a known medical issue, such as testicular damage. But evidence is growing that more men — and women — might benefit from the hormone, which is delivered through injections, patches, subcutaneous implants or gels. (This article uses ‘men’ and ‘women’ to reflect the language used by the panels and studies cited, while recognizing that trans, non-binary and intersex people are also affected by this issue.) The panel’s recommendations intensify a debate that has been brewing about who might benefit from the treatment. Some clinicians say that most men with low testosterone, especially young ones with no medical issue contributing to the problem, don’t need supplemental treatment at all and should be able to raise their testosterone levels by adopting a healthier lifestyle and losing weight. Others argue that men with low testosterone who have symptoms such as low libido, fatigue and irritability could gain from the therapy. The misunderstood sex chromosome: how X affects your health More-enthusiastic proponents, including many members of the FDA panel at the December meeting, take a third view: that all cis men should be tested, and those with low testosterone levels should be treated even if they have no symptoms. “You could make a very strong argument that having a normal testosterone level is important for health and prevention of illness,” says Abraham Morgentaler, a urologist at Harvard Medical School in Boston, Massachusetts, who took part in the December panel. Morgentaler and other panellists stressed at the meeting that testosterone is not just a ‘lifestyle drug’ that men take to build muscle and feel good. Yet it is increasingly being marketed that way. Podcasters such as Joe Rogan and his guests have sung the hormone’s praises. And scores of testosterone clinics are popping up around the world1, promising fitter bodies and a boost in energy levels to people who might not even have low testosterone to begin with. At high doses, testosterone use potentially comes with risks ranging from infertility to increased mortality. The drug is currently classified as a controlled substance with potential for abuse in the United States and several other countries, owing in part to doping scandals in the 1990s and 2000s. That classification is worth reconsidering according to statements made by FDA commissioner Marty Makary, who also voiced his enthusiasm for testosterone at the December panel. So what is the evidence for the safety and benefits of testosterone replacement? Safety record Testosterone’s reputation has had its ups and downs since the hormone was first synthesized in the 1930s. After an initial golden period, in which it was described as “one of the most potent drugs recently introduced to medicine”2, the therapy fell out of favour for fear that it could cause cancer. This idea originated from the work of urologist Charles Huggins who, in 1941, found that prostate cancer depends on testosterone and that lowering the hormone levels caused tumours to shrink3. It was a groundbreaking discovery for which he was awarded a share in the Nobel Prize in Physiology or Medicine in 1966. Morgentaler says that when he was training as a urologist in the 1980s, there was a widespread belief, based on Huggins’s findings, that testosterone therapy could promote prostate cancer. Despite the presumed risks, he says he still thought that the hormone could help some of his patients who had low testosterone and sexual problems. So, he started treating them while monitoring them closely. The surprising science behind red-light therapy — and how it really works They didn’t get cancer, Morgentaler says, and they benefited from the treatment greatly. Some of his clinical findings — along with the revelation that Huggins’s most dire warnings about the hormone causing cancer were based on observations of a single person — helped to clear the way for renewed interest in testosterone therapy. Morgentaler is widely recognized for his testosterone-safety work, although some clinicians disagree with him on how much men stand to benefit from the hormone. Morgentaler notes he has consulted for companies that sell testosterone in the past, but says that he has no current financial interests. Other potential risks cropped up over time. Two retrospective studies from 2013 and 2014 found an increased risk of heart attack in men on testosterone therapy4,5, which led the FDA to add a warning to testosterone product labels in 2015. But a randomized clinical trial involving around 5,200 men — called TRAVERSE — found that middle-aged and older men with low testosterone and a high risk of cardiovascular disease who took the hormone did not have a higher incidence of severe cardiovascular events, including heart attack and stroke, than did those on placebo6. “This study only picked very sick people, the greatest-risk population, and nothing bad happened to them,” says co-author Mohit Khera, a urologist at the Baylor College of Medicine in Houston, Texas. He also participated in the FDA expert panel and says that he consults for testosterone companies. On the basis of the TRAVERSE findings, the FDA removed the cardiovascular warning from testosterone products last year. The safety evidence from TRAVERSE refers to men with confirmed low testosterone levels — below 300 nanograms per decilitre of blood serum — who are treated to bring their levels back to the normal range of 350–750 nanograms. Higher doses, however, that push levels well above the natural range, carry radically different risks. Forget SkinTok: the real science of skincare and why it matters for your healt At high doses, testosterone can thicken the heart’s muscles, impairing its ability to pump blood, a condition called cardiomyopathy. High testosterone levels can also cause infertility, shrunken testicles, reduced sperm count and erectile dysfunction, says Channa Jayasena, an endocrinologist at Imperial College London. There are also neuropsychiatric effects, including irritability and even psychosis, which might increase the risk of violent crimes and domestic abuse, says Jayasena, who advises companies that sell testosterone, but says that he declines payment to avoid a conflict of interest. “For reasons we don’t fully understand, very high doses of testosterone do something that therapeutic testosterone doesn’t do,” he says. A Danish study7 that followed some 500 men using high doses of anabolic steroids — which include medically approved testosterone products and other variations of the hormone — found that their mortality rate was three times higher than that of non-users over a period of around seven years, a risk that Jayasena says is similar to that of cocaine use. The study participants were caught by a doping control programme that inspects fitness centres in Denmark and tests people suspected of steroid abuse. The authors acknowledge that steroid use has been associated with risk-taking behaviours, which could explain part of the increased mortality. This form of misuse is also addictive: about 30% of men on high doses become dependent. “They are flooding our clinics,” Jayasena adds. Who can benefit? Clinicians pushing for broader testosterone use often share striking anecdotes of the hormone transforming people’s lives. Morgentaler says that when he started treating people who had low testosterone levels in the late 1980s, they reported back things such as “My wife likes me again”, and “I’ve never had so much patience with my small children”. On a regular basis, they tell him that they finally feel like themselves again, with improved mood, vigour and libido. They go from feeling depleted, as if their fuel tank is empty, to regaining stamina and thriving at work, Morgentaler says. These accounts are from people who stay on the therapy; many drop out. In the TRAVERSE trial, around 61% of participants receiving testosterone discontinued treatment. There is limited research into why men stop testosterone, but Morgentaler guesses that some don’t like how it’s administered and others just don’t feel the benefit (perhaps, he argues, because they are taking the wrong dose or have unrealistic expectations). Clinical trials support only a modest portion of the benefits that testosterone fans tend to attribute to it. The clearest effect is in sexual function. A subanalysis of the TRAVERSE trial, which included around 1,100 men with low libido, found that both the treatment and the placebo groups increased their sexual activity, but the increase was 25% greater in treated men8 (see ‘Testosterone and sexual activity’). Sexual desire also improved with testosterone therapy, although erectile function did not (see ‘Testosterone and erectile dysfunction’). Source: Ref. 8 A meta-analysis commissioned by the Endocrine Society, an organization based in Washington DC, concluded that testosterone was associated with a “small but statistically significant” improvement in sexual function, sexual satisfaction and libido in men with low testosterone9. It also found a small improvement in erectile function, contrary to the TRAVERSE trial. The review found no statistically significant difference in energy, mood or cognition. Source: Ref. 8 Other studies have shown that testosterone treatment can effectively treat anaemia and that it improves bone density10. Surprisingly, men receiving testosterone in the TRAVERSE trial had more fractures than those on placebo11. “It must be that these inactive men were becoming more active”, which could be a good thing if that means they are getting more exercise, says Jayasena. Smaller trials showed that testosterone is also associated with an increase in fat-free body mass and muscle strength, both in younger and older men12. Potential benefits for women As testosterone use surges in some groups, many people who could benefit have mostly been left out of the debate, including trans men, for whom the hormone is recommended as a part of gender-affirming care, and postmenopausal women. For women, the only indication for which there is clear evidence of benefit is low sexual desire after menopause that causes distress, according to a systematic review and meta-analysis of 36 randomized controlled trials13. Susan Davis, an endocrinologist at Monash University in Melbourne, Australia, and a co-author of the review, says that there is huge variation in how women respond to testosterone therapy. Just having a physician listening to their concerns, validating them and caring for them is enough for some women to report feeling better. “I’ve now studied testosterone in thousands of women and probably done more clinical trials than anybody else with testosterone,” says Davis, who consults for companies that sell testosterone and has received grant funding from one. “What we’ve seen over and over again in all our studies is an incredible placebo effect.” Testosterone does do better than placebo in sexual function, but the data do not show a significant difference in well-being, cognitive health and body composition. The science influencers going viral on TikTok to fight misinformation Recommended doses — which aim to restore testosterone levels to those of premenopausal women — are generally safe, leading to side effects such as acne, and body and facial hair. High doses, however, are associated with side effects that some patients might find more unpleasant, such as hair loss, weight gain, voice change and an enlarged clitoris. “It’s pretty distressing,” says Davis. She has seen people who have been previously prescribed high doses and report agitation and aggression. Some say they’ve experienced road rage for the first time. “One woman told me she woke up in the middle of the night with her hands around her husband’s neck from a dream,” Davis says. Stopping treatment can also be challenging. Some women who suddenly stop after being on high doses “can feel very flat and miserable”, she says. Only four countries have testosterone products approved specifically for women: Australia, New Zealand, South Africa and, as of last year, the United Kingdom. Elsewhere, women are using testosterone formulations designed for men, which might put them at risk, Davis says. This type of off-label use is widespread in the United States. “It would seem to me that the FDA would actually be protecting women by approving a female dose-specific formulation,” she says. The FDA panel in December did not discuss testosterone use for women or for trans men. Regulatory hurdles The FDA currently limits approval of testosterone products to treat ‘classical hypogonadism’, in which low testosterone is caused by genetic conditions or disorders of the brain or testicles. In the United Kingdom, Europe and Australia, testosterone is approved for the treatment of men with laboratory-confirmed low testosterone accompanied by symptoms. They do not need to have an identified cause of the deficiency. This is also the position of most clinical guidelines from urology and endocrinology associations around the world. But the more restrictive regulatory scenario in the United States is already starting to change. In April, the FDA announced it was inviting pharmaceutical companies to submit applications for testosterone therapy for the treatment of low libido in men with low testosterone levels from an unknown cause. How to speak to a vaccine sceptic: research reveals what works So far, there have been no further changes to US regulations on the basis of proposals discussed by the expert panel, such as removing testosterone’s controlled-substance classification or recommending routine testosterone testing for all men. But more changes could still follow. One argument for including testosterone testing in routine preventive care, said panellist Helen Bernie, a urologist at Indiana University in Carmel, is that low levels have been associated with a range of health risks. For example, Bu Yeap, an endocrinologist at the University of Western Australia in Perth, and his colleagues have reported that older men with low testosterone have a higher risk of stroke14. At very low levels, the risk of death from any cause and from cardiovascular disease also increases15. Their work also linked low testosterone to a higher risk of dementia and Alzheimer’s disease16. “We are really aware from the work we’ve done that low testosterone is quite a robust biomarker for poorer health outcomes, particularly in older men,” says Yeap, who has advised and received research support from companies that sell testosterone. But, he adds, the data do not justify testing asymptomatic men. “If you treat all men with low testosterone, will it actually prevent ill health? We haven’t proved that.” Answering that question would require a large randomized clinical trial, potentially involving 10,000 older men with low testosterone and increased risk of poor health, followed for at least four years, Yeap says. His team is now working to get funding for such an initiative, which he anticipates will be expensive and complex. “But you’ve got to get the evidence,” he says. “You can’t just pre-emptively make assumptions, which is what some people might be doing.”
发布时间:2026-05-05 Nature
Research papers are increasingly being written by artificial intelligence.Credit: Yagi Studio/Getty How much of the scientific literature is generated by AI? The first studies of the size of the AI footprint in scientific journals, preprint repositories and peer-review reports give a spread of answers — and indicate a rapidly evolving situation that it is difficult to get a handle on. The fear of many in the research community is that poor-quality or entirely fabricated research produced by large language models (LLMs) could overwhelm the ability of current quality-control systems to detect it, thereby polluting the scientific canon. “The ground is shifting underneath us in ways that we are totally unprepared for,” says Maria Antoniak, a computer scientist at the University of Colorado Boulder. “We live in an escalating arms race” between people using AI unscrupulously and those who are trying to constrain or detect it, says Richard She, a stem-cell biologist at Nanyang Technological University in Singapore. Source: ref 1. AI detectors Concerns about the extent of AI-generated content in the scientific literature mirror broader online trends. At the end of March, AI-generated articles were estimated to outnumber those written by humans, according to an analysis of 55,000 newly published webpages shared with Nature by the private firm Graphite in San Francisco, California. LINK AI tool detects LLM-generated text in research papers and peer reviews AI might have legitimate uses in the production of scientific literature, and can accelerate research progress. But AI-generated content is also potentially problematic because it can be used to create fake or low-quality papers. To investigate this, researchers are turning to AI-detection tools to measure the scale of the issue. Some of the available tools don’t distinguish between text that was merely edited with AI, and text that was wholly generated by it. The systems also have varying ways of defining what counts as ‘AI generated’, and can falsely flag human-written text as AI generated. Nevertheless, they can provide some pointers as to what the trends in the use of AI are. Droplets in a storm In a study published on 27 April1, researchers used a tool developed by Pangram Labs in New York City to scan nearly 7,000 manuscript abstracts submitted to the journal Organization Science between January 2021 and February 2026, along with some 8,000 peer-review reports. It is the first analysis to estimate the overall amount of AI-generated content in a research journal’s review process, the authors say. The study reported a 42% increase in submissions since November 2022 — when ChatGPT was released as the first LLM available to the general public — and found that the increase was driven mainly by AI. The authors also estimated that by February this year, submissions with more than 70% AI-generated text had more than doubled compared with the numbers seen in early 2024 (see ‘AI-written text in scientific journals is rising’), and more than 30% of peer-review reports also contained some AI-generated text. Other researchers, including She and Antoniak, have been attempting to record the total amount of AI-generated research content that currently exists online — a near-impossible task owing to the sheer volume of papers involved. She used Pangram's AI detection tool to screen some 5,000 biomedical science papers published last year in journals including Science, Nature and Cell. His analysis — published in a January preprint2 — found that six papers were flagged as fully AI-written, but one in eight articles contained some AI-generated text. She expects the rate to go up in the coming years. “We’re at the very, very beginning of this new era. What we’re seeing is the first droplets of a storm that’s incoming,” he says. In another preprint published in January3, Antoniak and her colleague used two AI-detection methods to screen more than 124,000 manuscripts posted on arXiv between 2020 and 2025. They found that for computer science, review preprints containing AI-generated text increased from about 7% in 2023 to 43% in 2025. Non-review manuscripts in this field that contained AI-generated text also grew from around 3% to 23% during the same period. Antoniak’s study did not consider the distinction between manuscripts that might be wholly AI-written and those with just some AI-generated text. It also did not “make any judgement about the quality of the work”, she notes. Best guess A broader issue is the lack of accurate and reliable methods to record precisely how much of the broader scientific literature is AI generated. “It is very complicated, both as a quantitative problem of how we can quantify, in a reliable way, these rates — because we don’t have a ground truth — and because there are these different ways of using AI,” says Antoniak. Major AI conference flooded with peer reviews written fully by AI Detectors will need to get more sophisticated to keep up with ever-improving AI models, says She. “You’re going to have more and more mechanisms by which people will try to humanize their text and try to evade the detectors,” he adds. Alongside AI detectors, approaches such as ‘watermarking’ could help to screen out undisclosed use of AI in future. A major AI conference recently used an innovative watermarking technology to detect AI-generated text in peer reviews of other articles submitted to the meeting. This led to 497 papers being rejected. Such tools are at an early stage of development. And until they “can enable us to distinguish between AI-generated and AI-enhanced text more readily, we still need to be very sceptical of those studies that try to assess how much of the literature or how much of the internet is AI generated now”, says Mohammad Hosseini, who studies research ethics and integrity at Northwestern University Feinberg School of Medicine in Chicago, Illinois.
发布时间:2026-05-05 Nature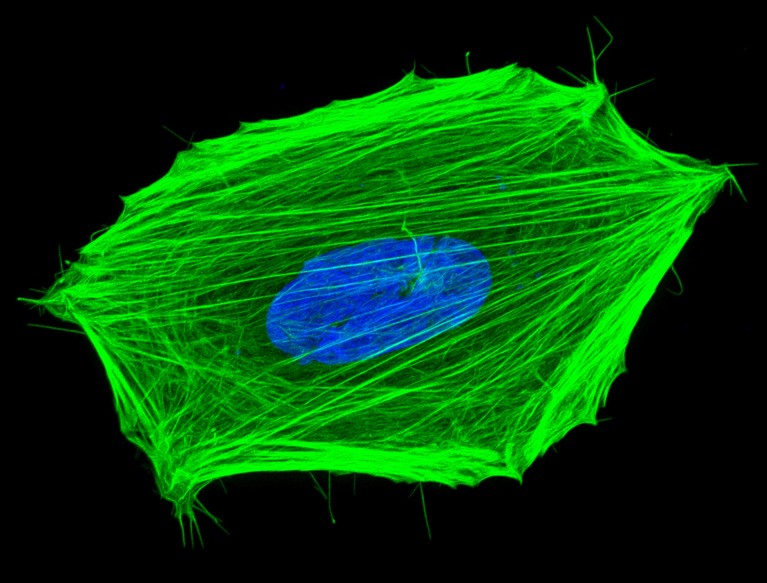
A cancer cell (nucleus in blue, cellular ‘skeleton’ in green). Scientists have devised nanosensors that can measure the temperature inside cancer cells, including the cell nuclei.Credit: Howard Vindin, The University of Sydney/Science Photo Library To check your temperature, doctors place a thermometer under your tongue. Researchers have now created a thermometer small enough to check the temperature of a single living cell, and even individual cellular regions, such as the nucleus. Once refined, similar technologies could help scientists to study metabolism and other chemical reactions of life on the smallest scale. The work was reported last Wednesday in Science Advances1. Why ‘quantum proteins’ could be the next big thing in biology Before now, the best cell thermometers were nanodiamonds with defects known as nitrogen-vacancy centres. But each diamond is slightly different, meaning that readings are not consistent across sensors. The authors of the new paper created an alternative: molecular quantum nanosensors. The team embedded molecules of a hydrocarbon compound called pentacene into a crystal. Then they tumbled the crystal to break it into smaller particles, coating them in a polymer during this process to prevent clumping and maintain their safety to cells. The final sensors were either 200 or 500 nanometers across, a small fraction of the diameter of a human red blood cell. These sensors are considered quantum because their behaviour depends on ‘superpositions’ between particular quantum states of the pentacene molecules’ electrons — that is, the electrons are occupying multiple states at once. Green light, red light Shining green lasers at the sensors made them glow red. But simultaneously stimulating the sensors with microwaves at certain frequencies slightly dimmed their glow. The temperature of the sensors’ surroundings (and, by extension, the sensors themselves) affects the dim-inducing frequency. The authors worked out the precise relationship between the frequency that triggered dimming and temperature, allowing them to infer one from the other. Quantum correlations enhance the sensitivity of room-temperature sensors To get the sensors inside cells, the scientists either bathed cancer cells in solutions containing the sensors until they were absorbed or injected them into the nuclei. The team then applied their laser-and-microwave system to the sensors and noted which frequencies of microwaves caused them to dim, an index of cellular temperature. They refined the sensors and found that the upgraded versions of the molecular quantum sensors were highly accurate. What’s more, measurements made by several sensors fell within 0.3 ºC of each other. By contrast, nanodiamond sensors yielded temperature measurements that varied by several degrees. Using the new nanosensors, the researchers found that the temperature of different parts of the cell varied by as much as 1 ºC. Even more nano Using molecules, rather than vacancies, for quantum sensing in living cells is “really, really cool, really amazing”, says study co-author Nobuhiro Yanai, a chemist at the University of Tokyo. Hitoshi Ishiwata, a quantum engineer at the Institute for Quantum Life Science in Chiba, Japan, and study co-author, says that a strength of the platform is that the researchers can independently engineer the sensor molecule, host crystal and particle coating. “I think it’s a fantastic milestone,” says Sarah Mann, a physicist at the University of Glasgow, UK, whose team has demonstrated ways to control and measure pentacene molecules at room temperature2. “It’s exactly where I hoped my own research into these materials would lead. It will be so useful for disease detection.” The authors of the new paper found that they could measure not only a cell’s temperature, but also other factors, such as levels of oxidative stress. The current version of the sensors did no measurable damage to cells. But to increase their system’s usefulness, Yanai says, the researchers want to make the nanoparticles even more nano to avoid disturbing biological processes. Success, Yanai says, would let them “spy on cellular activities”.
发布时间:2026-05-05 Nature
Grants terminations requested by the administration of US President Donald Trump last year disproportionately affected researchers from under-represented groups, a survey suggests.Credit: Loic Venance/AFP via Getty The abrupt termination last year of thousands of research grants by the US National Institutes of Health (NIH), the world’s largest public funder of biomedical research, didn’t affect all groups of scientists equitably. A survey suggests1 that it disproportionately hit researchers from groups that have been historically under-represented in the biomedical sciences, including women, people of colour and investigators from sexual and gender minorities (LGBTQ+). US science after a year of Trump: what has been lost and what remains Although some of these cancelled grants were later restored, researchers fear that the cuts — many of which targeted studies on health equity and gender-related issues — will change the demographics of who is doing science in the United States. That, in turn, could widen existing knowledge gaps about populations that are already underserved by the US health-care system, researchers say. Many scientists who research a specific community tend to come from that community themselves, says Donna Ginther, an economist at the University of Kansas in Lawrence, who studies scientific labour markets. “Who’s based in the sciences gets to influence what questions are being asked, so when diverse investigators and scientists are pushed out, then those questions are also pushed out,” adds Arjee Restar, a social and legal epidemiologist at the Yale School of Public Health in New Haven, Connecticut. The NIH did not comment on the survey or scientists’ concerns about the findings. A spokesperson responded to Nature with a statement about the agency’s grant-review system, saying that the “NIH supports a fair and objective review process that evaluates proposals based on scientific merit, methodological rigor, and potential contribution to the field”. Research defunded Officials in the administration of US President Donald Trump began terminating already-funded grants at the NIH in February 2025, cancelling more than 2,000 grants by the end the year. The administration targeted research topics that it deemed wasteful or politicized, including misinformation, vaccine hesitancy, infectious diseases and research on people from under-represented ethnic and gender groups — which it has called discriminatory and unscientific. Some of the grants were later restored because of negotiations with universities and lawsuits. Trump team’s science cuts threaten tenure hopes for early-career academics Rebecca Fielding-Miller, a social epidemiologist at the University of California, San Diego, and her colleagues wanted to understand who these cuts affected, so they sent a survey to the corresponding authors, or investigators, of approximately 2,000 terminated grants. The results of their analysis are published today in The Lancet Regional Health – Americas1. About 940 researchers responded to the survey. Of the people who had lost grants that were focused on health-equity topics, nearly half of them identified as Black, Indigenous or as a person of colour (BIPOC). (In 2024, the NIH awarded 7% of its grants to Hispanic and Latino researchers and 4% to Black researchers, suggesting that BIPOC individuals were disproportionately affected by the terminations.) Among grants terminated because they were funding gender-related studies, 60% of the investigators identified as LGBTQ+, including more than 15% who were transgender or nonbinary. And LGBTQ+ researchers had more than ten-fold higher odds of losing a grant for a gender-related study than did their counterparts who did not identify as LGBTQ+. According to NIH data from 2024, 42% of grants were awarded to women. However, 56% of survey respondents self-identified as women, pointing to female scientists being disproportionately affected by the terminations. The cuts threaten to exacerbate an entrenched funding gap at the agency, Ginther says. For example, a 2023 study2 that analysed three decades of NIH data found that even before the latest cuts, Black female researchers were 71% less likely than their white male colleagues to hold more than one concurrent grant, and women overall were 34% less likely to hold several simultaneous grants than were men. Precarious careers Another study, published in March in Proceedings of the National Academy of Sciences3, similarly found that grant terminations at the NIH disproportionately affected early-career researchers, as well as women. The analysis revealed that although female scientists tended to receive less money than their male colleagues on average, they tended to have more money remaining on their grants at the time of termination. So when the grants were cancelled, a larger share of their money was rescinded, halting salary payments and research activities for individuals who were “especially vulnerable to abrupt changes”, the authors of the paper wrote. The consequences of these funding disruptions extend beyond individual scientists. Restar says that a single grant supports an “entire village of people”, including students, postdocs and study participants. Ginther warns that the shifting priorities of the Trump administration have already pushed graduate students to reconsider biomedical careers altogether, “killing discoveries that may contribute to health in the future”, she says. “The biomedical career is highly precarious, and when there’s such a change in the funding landscape, it makes what is really risky to begin with appear to be unattainable.”
发布时间:2026-05-05 Nature